
导读1.4爬虫工程师常用的库通过图1-3我们了解到,爬虫程序的完整链条包括整理需求、分析目标、发出网络请求、文本解析、数据入库和数据出库。其中与代码紧密相关的有发出网络请求、文本解析、数据入库和数据出库
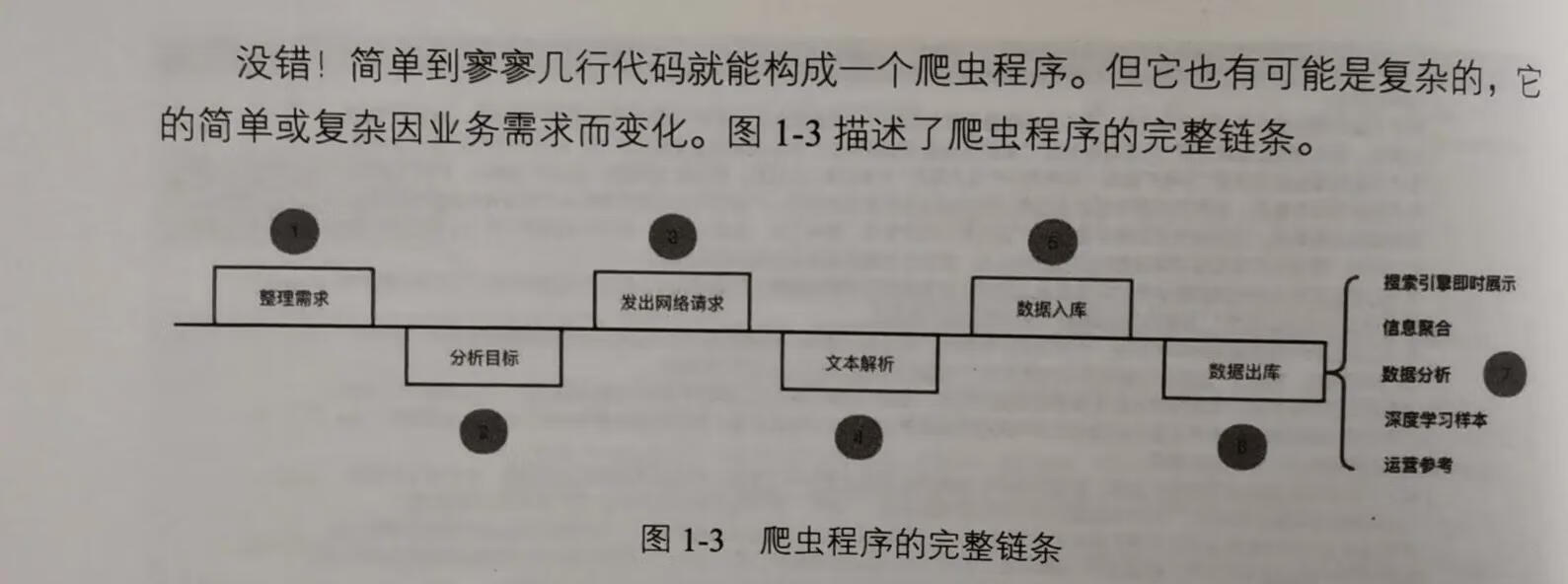
1.4爬虫工程师常用的库通过图1-3我们了解到,爬虫程序的完整链条包括整理需求、分析目标、发出网络请求、文本解析、数据入库和数据出库。其中与代码紧密相关的有:发出网络请求、文本解析、数据入库和数据出库,接下来我们将学习不同阶段中爬虫工程师常用的库。我们没有必要学习具备相同功能的各种各样的库,只需要选择其中使用者较多或比较称手的即可。例如,网页文本解析库有BeautifulSoup、 Parsel 和HTMLParser,但我们只需要学习Parsel就够了,这就像学习如何驾驶汽车时你不需要学习同类型车辆的驾驶方法一样。
1.4.1 网络请求库
网络请求是爬虫程序的开始,也是爬虫程序的重要组成部分之一-。 在代码片段1-1中,我们使用的是Python 内置的urlib模块中request对象里的urlopen0方法。其实代码片段1-1中的代码已经非常简洁了,但持有“人生苦短”观念的Pyhon工程师认为我们需要用更简单且编码速度更快的方法,所以他们创造了Requets 库和Aiohtp库,知名的爬虫框架Scrapy也是这么诞生的。
免责声明:本文章由会员“丁原东”发布如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系